Chapter 17 Common Types of Graphs
In this chapter, you will learn how to create some of the most commonly used graphs, including bar plots, box plots, histograms, and scatterplots. These powerful visualization tools will enable you to explore and communicate your data effectively, gaining valuable insights along the way.
17.1 Bar Charts
Bar charts, also called column charts, represent categorical data with rectangular bars whose height/length is proportional to the values they represent.
ggplot(data = sumAtl,
aes(x = city,
y = mean)) +
geom_col() +
coord_flip() +
labs(x = "City in Atlantic Canada",
y = expression(Mean~NO[2]~(ppb)))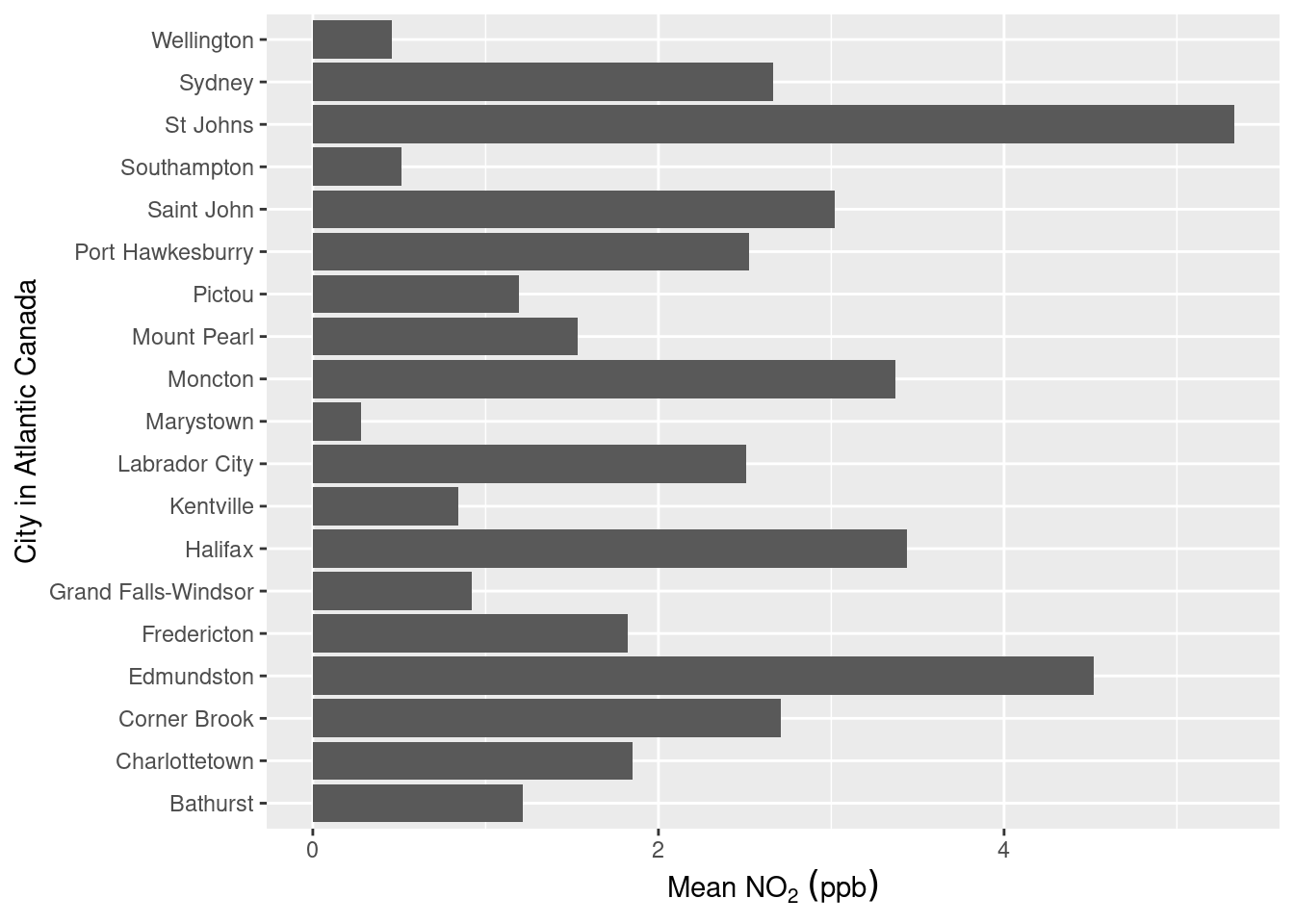
Not an overly exciting plot, but it gets the job done showing the mean NO2 concentrations in each of the Atlantic Canada provinces (remember this dataset was created in the Summarizing Data chapter). Let’s break down the code:
ggplot()includesgeom_col()andgeom_bar(). While both can be used to make bar charts.geom_col()is used when you want to represent values in the data (i.e. the precalculated mean as shown above), whereasgeom_bar()makes the height of the bar proportional to the number of cases in each group.To our aesthetic mappings we’ve specified which values from the
sumAtlare supposed to be our x-axis (x = city) and y-axis (y = mean).We used
coord_flip()to rotate our plot 90\(^\circ\) therefore the suppliedxoption ofcityis now plotted on the vertical axis. This makes reading long categorical names (i.e. the names of cities) easier.coord_flip()doesn’t change anything else except the final orientation of the plot.We used
labs()to provide clearer labels for our axes than those defined by the column titles. Note that because we flipped the axes the y-axis is the horizontal axis and the x-axis is the vertical axis. Also note the use of theexpression()function within the y-axis label, this is because subscripts and superscripts are not possible in thelabs()function. The way that in that theexpression()function works is a bit strange, you specify a space between characters/words by using a tilde ~, a subscript is specified by square brackets [], and superscript by a caret ^.
17.1.1 Adding Error Bars
Almost all measurements have associated uncertainty/variability. These values are expressed visually via error bars demarcating the minimum and maximum variability and give a general idea of how precise a measurement is. In the Further Summarize Operations section we used the standard deviation (sd) function to calculate the standard deviation of the mean NO2 concentration in each city in the sumAtl dataset as a measure of the variability around the mean.
To include these standard deviation values as error bars we can use the geom_errorbar() and pass the min and max values we want the error bars to be. In our case, the lowest value would be ymin = mean - sd, and the highest would be ymin = mean + sd. Our plotted error bars now indicate plus or minus one standard deviation from the mean.
ggplot(data = sumAtl, aes(x = city, y = mean)) +
geom_bar(stat = "identity") +
geom_errorbar(aes(ymin = mean - sd,
ymax = mean + sd)) +
coord_flip() +
labs(x = "City in Atlantic Canada",
y = expression(Mean~NO[2]~(ppb)))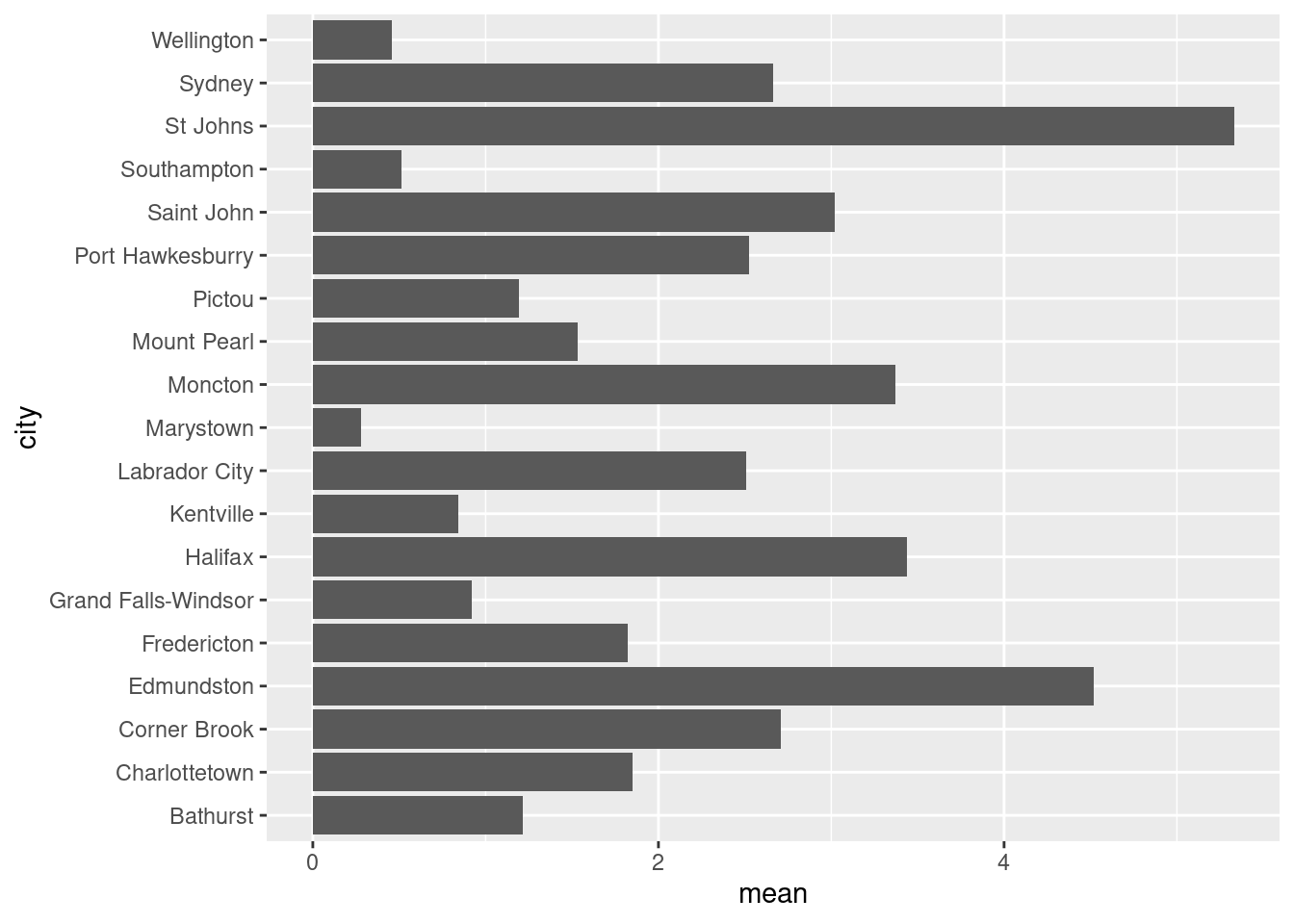
Some of the error bars indicate we could get a negative concentration of NO2. This is physically impossible, but it does suggest we should evaluate the distribution of our data (see below). Note that since we’re calculating error bar ranges on the fly, we’ve had to specify new aesthetic arguments to geom_errorbar().
17.1.2 Ordering Bar Charts
Often with bar charts (and similar plots), it’s useful to order the bars to help tell a story or convey information. We can do this using fct_reorder():
ggplot(data = sumAtl,
aes(x = fct_reorder(city, mean),
y = mean)) +
geom_bar(stat = "identity") +
geom_errorbar(aes(ymin = mean - sd,
ymax = mean + sd)) +
coord_flip() +
labs(x = "City in Atlantic Canada",
y = expression(Mean~NO[2]~(ppb)))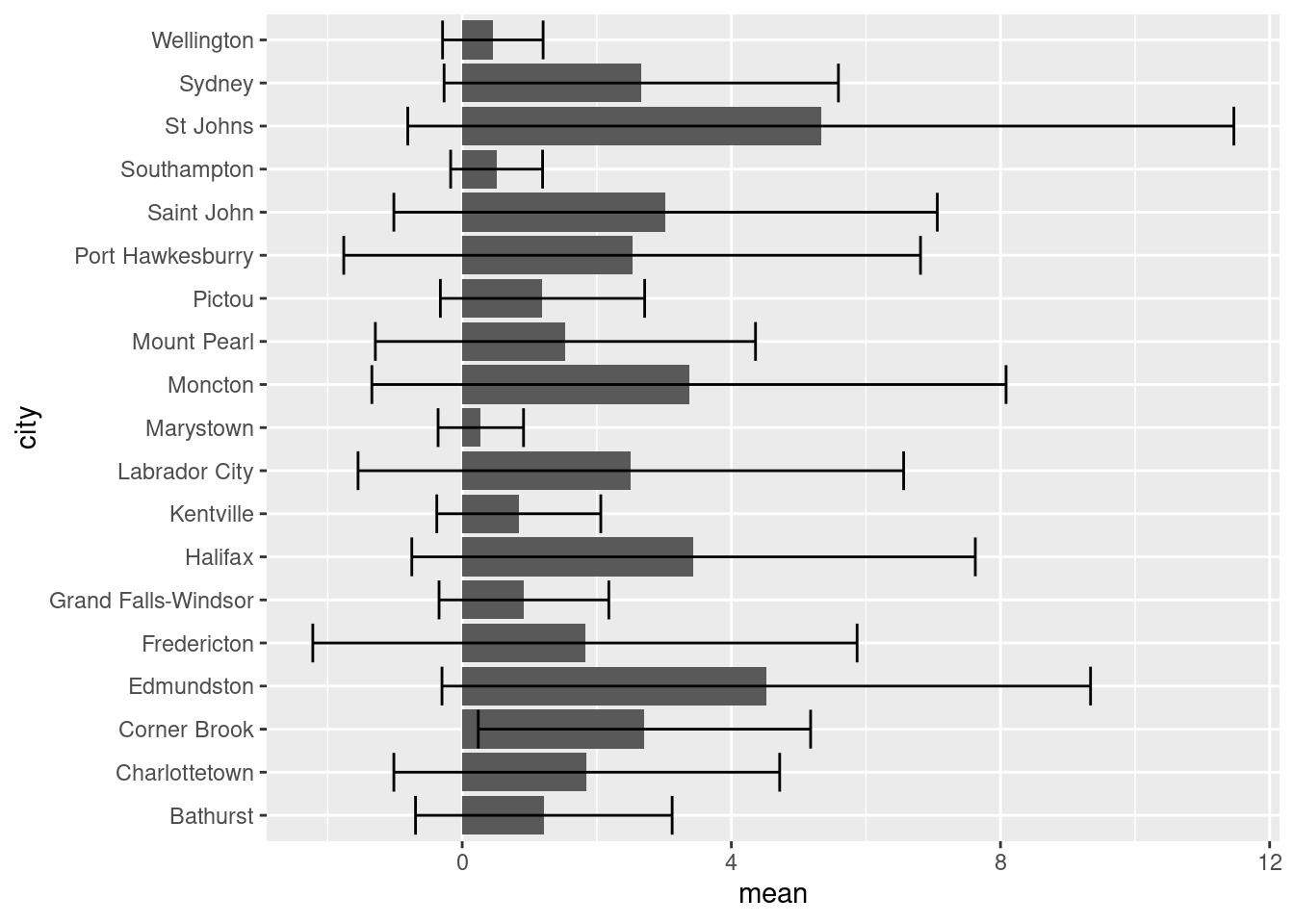
So in our aesthetics call for geom_bar we specified the x variable should be city, but ordered based on their corresponding mean value. Doing this has helped shed some light on trends in NO2 levels. For one, despite Labrador City having lower mean [NO2], we can now easily see that it has a larger variation in [NO2] than Corner Brook.
17.1.3 Grouping Bar Charts
Sometimes you’ll want to create groups within your bar charts. One example of this in the atldata dataset is to group the cities by province. To visualize trends within each province in the code below we decided to:
Reorder the cities based on province using the
fct_reorder()function that specifies which variable is being ordered (city) and what information is being used to order it (pcolumn).Colour the bars based on province using
fill = p.
ggplot(data = sumAtl,
aes(x = fct_reorder(city, p),
y = mean,
fill = p)) +
geom_bar(stat = "identity") +
geom_errorbar(aes(ymin = mean - sd,
ymax = mean + sd)) +
coord_flip() +
labs(x = "City in Atlantic Canada",
y = expression(Mean~NO[2]~(ppb)))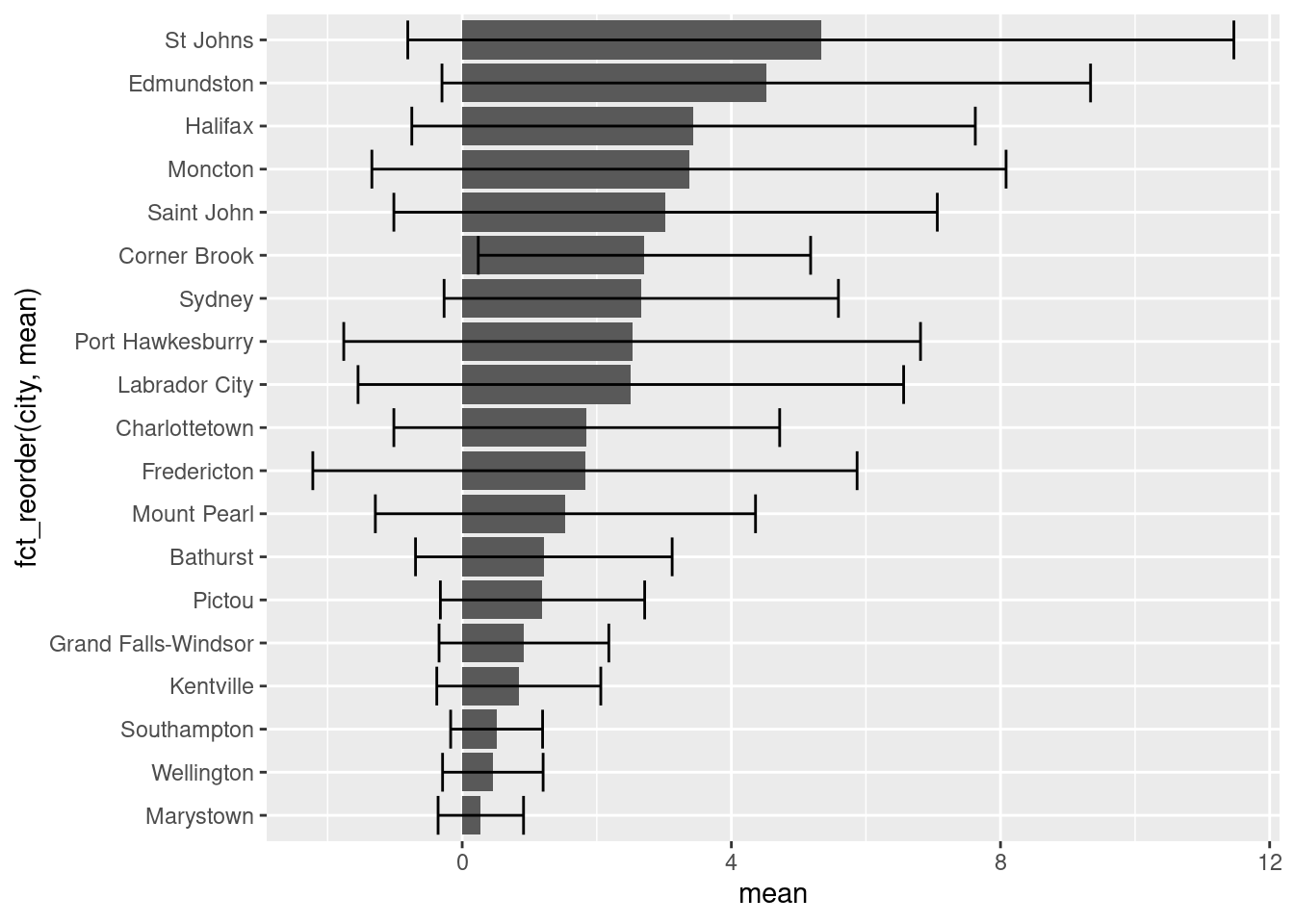
There are other ways to group your bar charts depending on the story you want to tell and the data you have. Please consult the Grouped, stacked and percent stacked barplot in ggplot2 page from the R-graph-gallery.
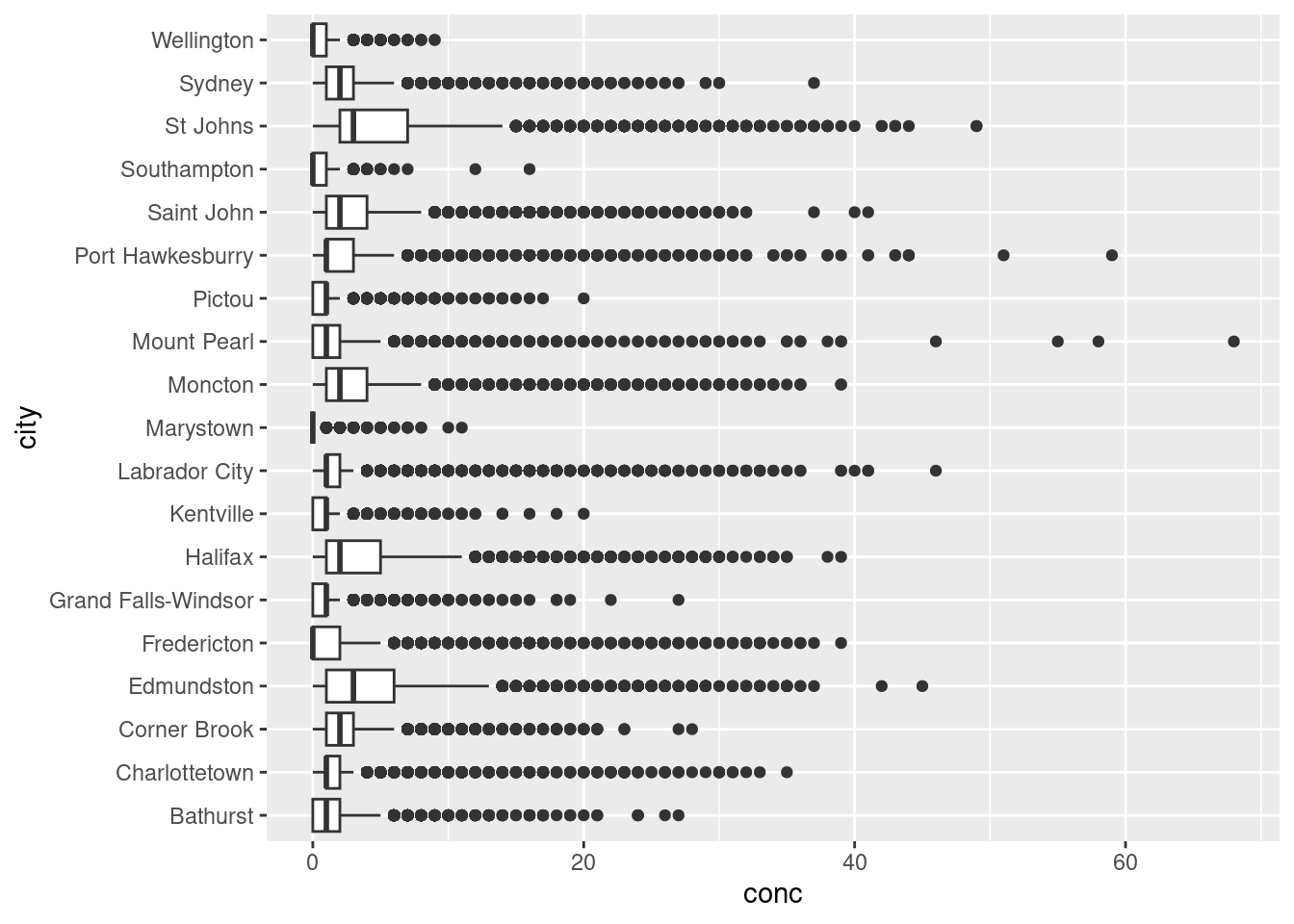
17.2 Box Plots
Box plots give a summary of the distribution of a numeric variable through their quartiles. You’ve no doubt seen them before, but they’re often misinterpreted. Let’s create a box-plot using geom_boxplot() and our Atlantic hourly NO2 measurements, then we’ll break down how to interpret it.
ggplot(data = atlNO2,
aes( x = city, y = conc)) +
geom_boxplot() +
coord_flip() +
labs(x = "City in Atlantic Canada",
y = expression(Concentration~NO[2]~(ppb)))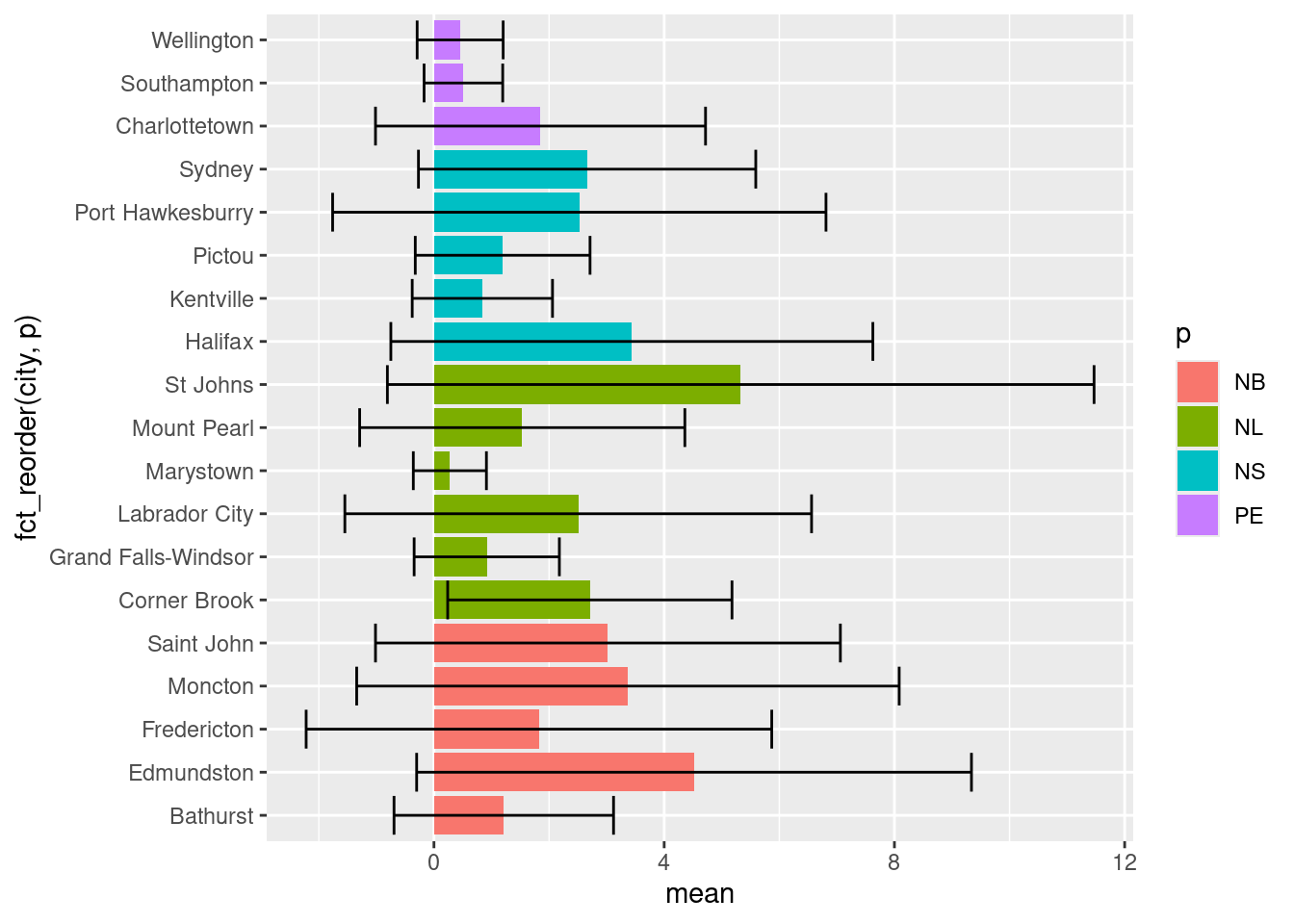
Let’s break down how to interpret one box before tackling the entire set. As previously mentioned, box plots describe data in their quartiles. Quartiles basically arrange the data from the lowest to highest value and split the data at three points:
- The first quartile (Q1) is halfway between the lowest value and the median (50%) of the data. In other words 25% of the data lies below Q1.
- The second quartile (Q2) is the median. 50% of the data lies below, and 50% lies above this point.
- The third quartile (Q3) is halfway between the median and the highest value in the data. In other words, 75% of the data lies below Q3.
The box in box-plots represents the range between Q1 and Q3. This is known as the inter-quartile range (IQR) and 50% of the total data falls somewhere inside this box. You can estimate the distribution by the symmetry of the box. if Q1 to the median is smaller than the median to Q3, the data has a positive skew (right sided skew), and vice versa.
Rounding it out, geom_boxplot() includes whiskers, the thin lines emanating out from the box. This is used to predict outliers and is calculated as \(outliers = \pm 1.5 \times IQR\). Anything outside the whiskers is considered an “outlier” or an extreme point, and is plotted individually.
Putting this all together, let’s look at the [NO2] for St. Johns city:
Note that we’ve plotted the actual distribution of the data. Prior to computers, this was incredibly difficult to do, hence the use of box plots which can be drawn knowing only five points. However, the simplicity in calculating box-plots means they can hide trends and observations of your data. A useful alternative to box-plot are Violin Plots, which are explored in the next section.
17.2.1 Violin Plots
Violin plots are made using geom_violin(). It is similar to the box-plot, but instead of displaying the quartiles, it plots the density within each group and is a bit more intuitive than box-plots. While the example below isn’t the most convincing given the scale of the dataset, violin plots are useful for identifying underlying trends in the distribution of data. For example, in the plot below we can see that some towns such as Marystown has days where [NO2] = 0 ppb, whereas Grand Falls-Windsor has a large number of days with low, but measurable levels of NO2. This might be because of differences in regional ambient levels of NO2.
ggplot(data = atlNO2,
aes(x = city, y = conc, fill = p)) +
geom_violin() +
coord_flip() +
labs(x = "City in Atlantic Canada",
y = expression(Concentration~NO[2]~(ppb)))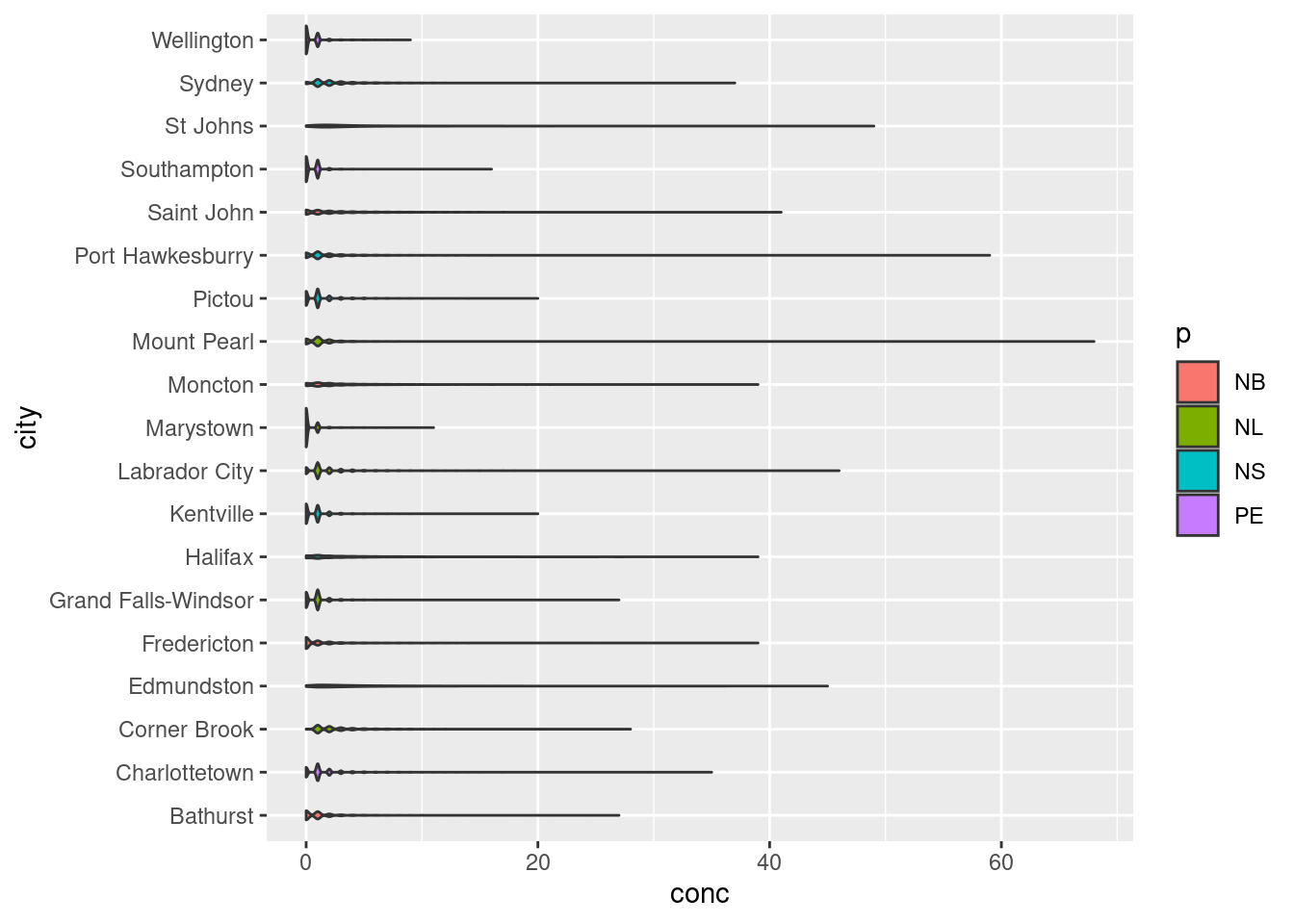
17.2.2 Statistical Comparisons Between Groups
Often box-plots are used to show differences in distributions between two groups (i.e. population in Location A vs. Location B). How you determine this statistically is a different story, but packages such as ggpubr have many built-in functionalities to display the results of these outcomes.
From our NO2 data, St. Johns appears to have the highest levels of NO2. Let’s apply a pairwise test against other Newfoundland communities to see if our observation is statistically significant based upon the results of a Wilcoxon test.
nfld <- atlNO2 %>%
filter(p == "NL") # only Newfoundland stations
# Code from ggpubr website
ggpubr::ggviolin(nfld, x = "city", y = "conc") +
ggpubr::stat_compare_means(ref.group = "St Johns",
method = "wilcox.test",
label = "p.signif") 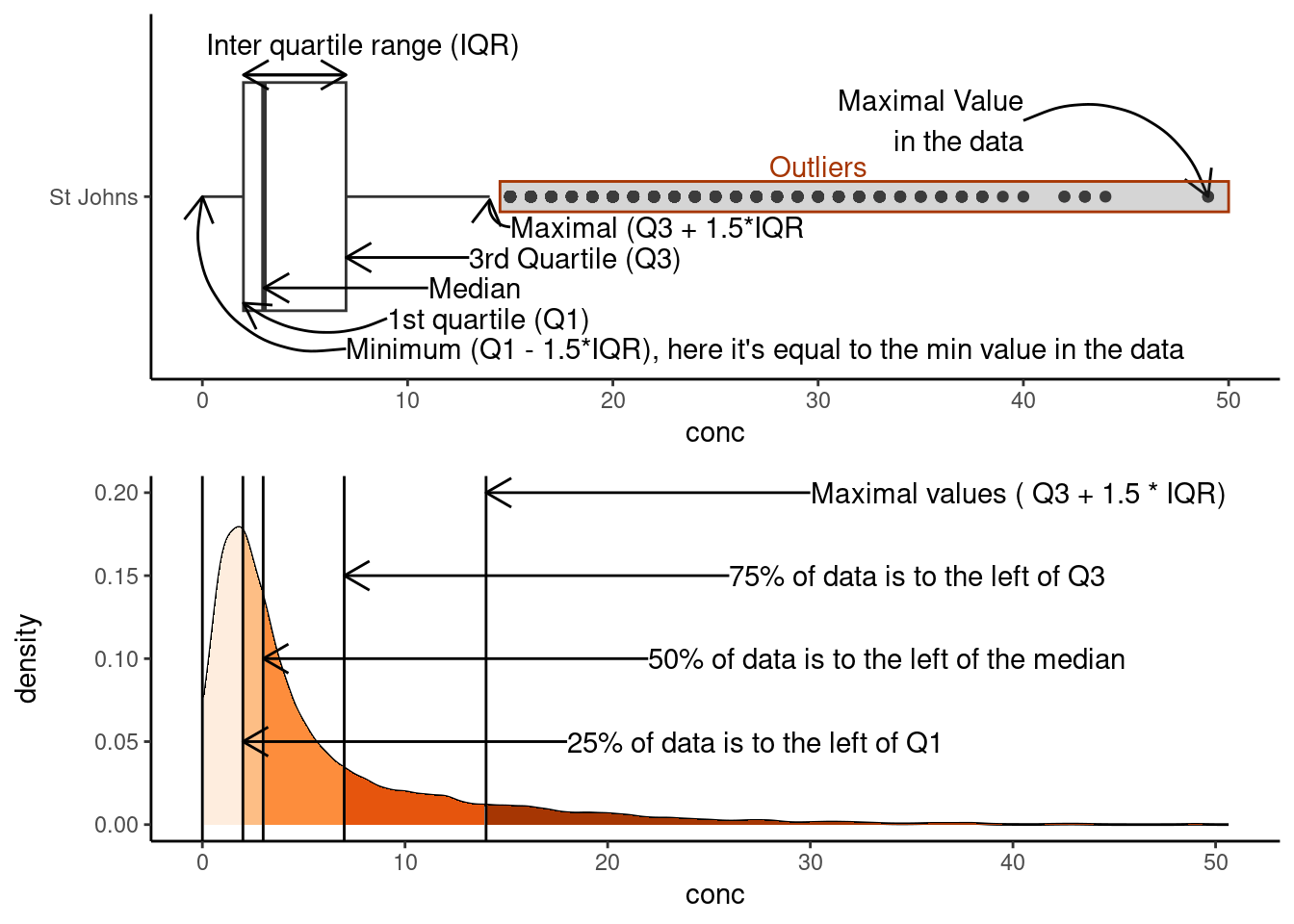
Based on the results of our test, all other stations in Newfoundland have statistically significant differences in the median NO2 values. Note the validity of this statistical approach to this particular problem is called into question based on the distribution of the data etc. We’ve included it to demonstrate how to label significance on plots, rather than an explicit discussion on statistics.
For more information on ggpubr, adding p-values and significance labels, and different pairwise statistical test please visit ggpubr: Publication Ready Plots.
17.3 Histograms
Histograms are an approximate representation of the distributions of numerical data. They’re an approximation because you arbitrarily “bin” your data into groups and then count the number of values inside that bin. The frequency, or count, in each bin is represented by the height of a rectangle whose width equals that of the bin. geom_histogram() is used to create histograms:
ggplot(data = filter(atlNO2, city == "St Johns"),
aes(x = conc)) +
geom_histogram() +
labs(subtitle = "Distribution of St. Johns' NO2 levels in 2018",
y = expression(Concentration~NO[2]~(ppb)))## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.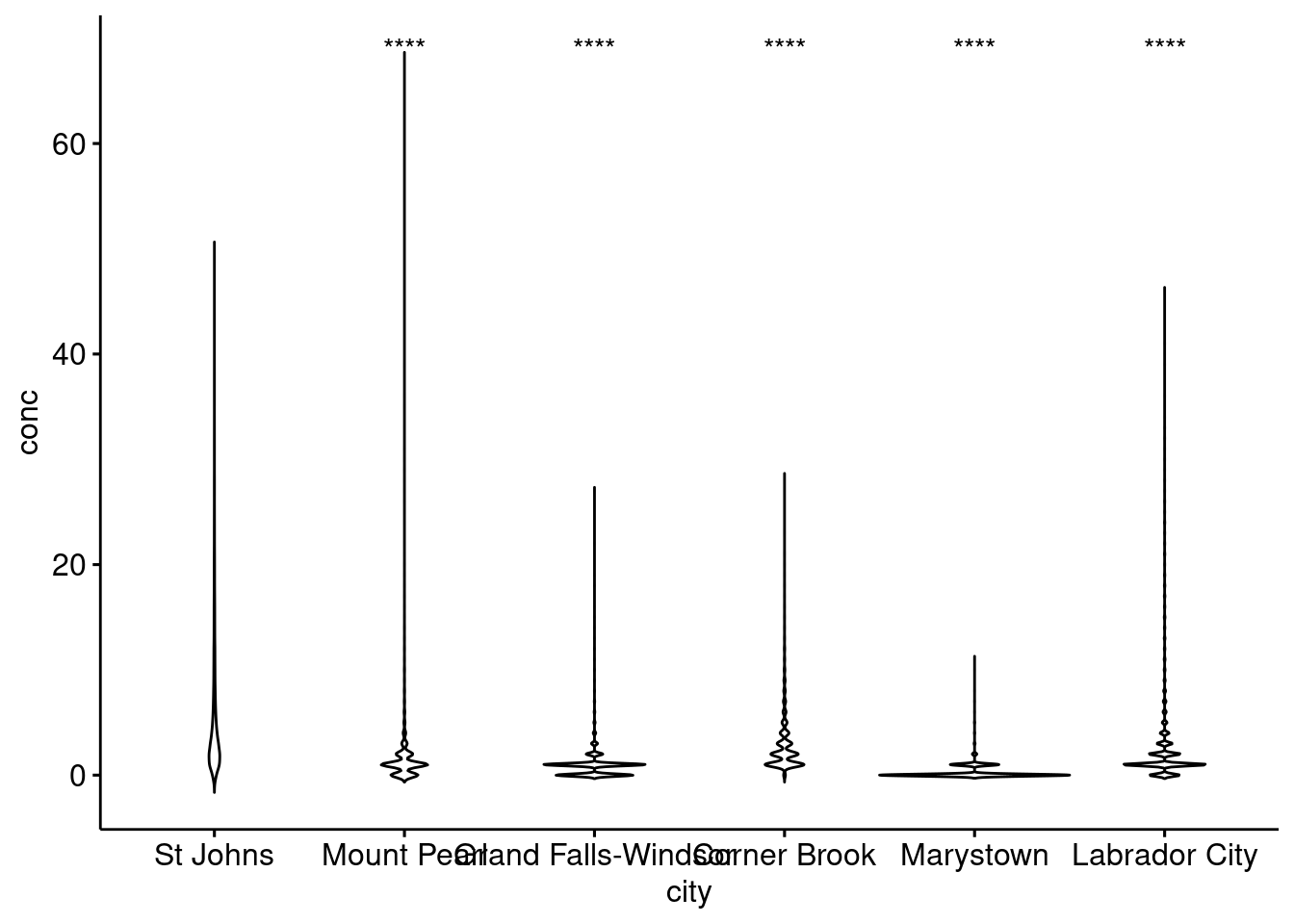
We can alter the resolution of our histogram by modifying the width of the bins using the binwidth argument or by specifying the number of bins with the bins argument. The former is useful when you don’t know the range of your data, whereas the latter is useful is you do (i.e. numbers between 0 and 100).
ggplot(data = filter(atlNO2, city == "St Johns"),
aes(x = conc)) +
geom_histogram(binwidth = 1) +
labs(subtitle = "Distribution of St. Johns' NO2 levels in 2018, binwidth = 1")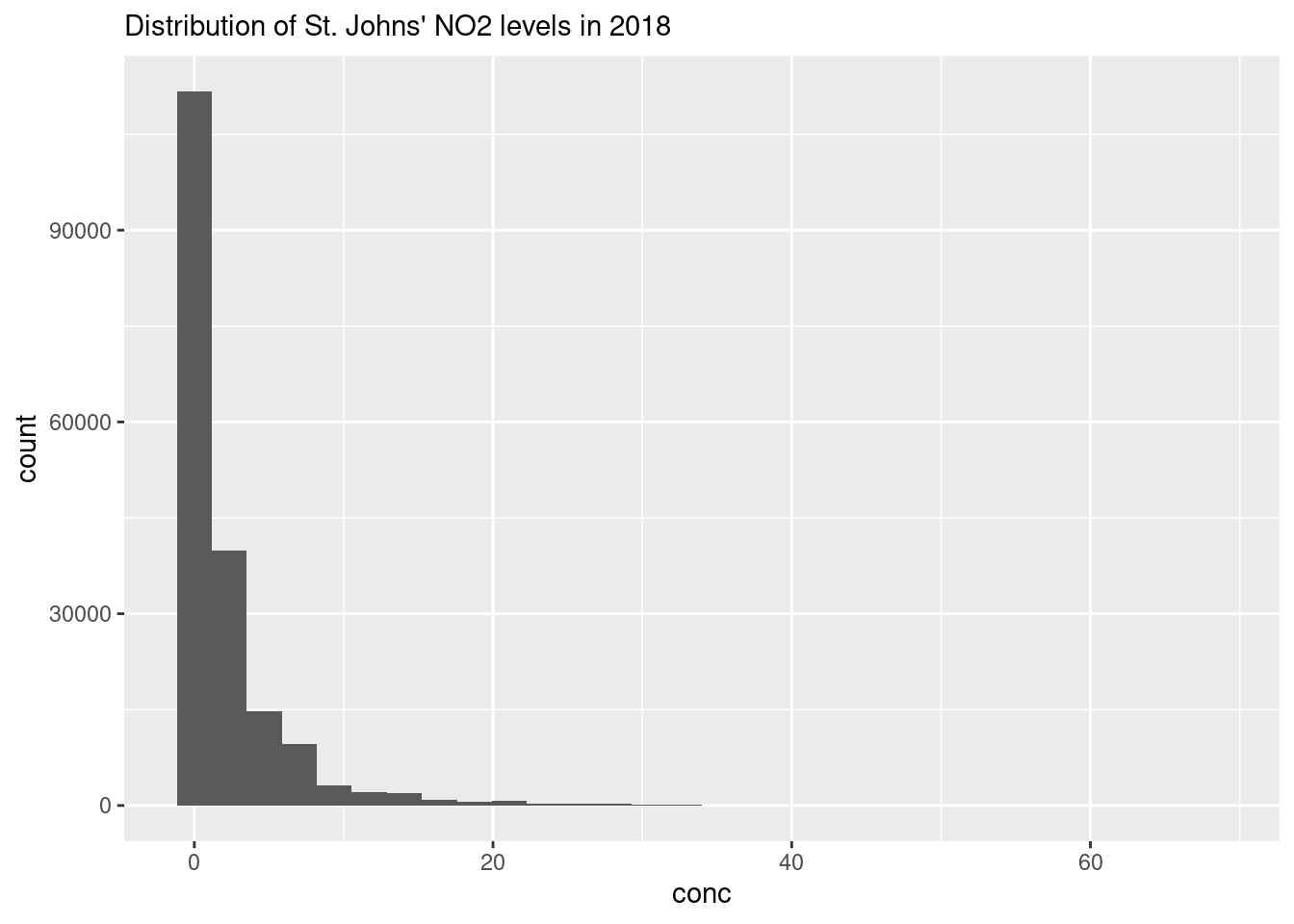
17.3.1 Multiple histograms
While you can overlap histograms, it gets difficult to read with more than a handful of datasets. If we wanted to plot histograms of all the cities in our dataset we would have to use a small multiple via the facet_grid() or facet_wrap() arguments. facet_grid() allows you to arrange many small plots on a grid defined by variables in your dataset (i.e. columns for provinces, and rows for different pollutants). In the example below we’ve used facet_wrap(~city) which creates a 2D layout of histograms of each cities NO2 values. Note the tilde , ~, preceding in ~city.
ggplot(data = atlNO2,
aes(x = conc, fill = p)) +
geom_histogram(binwidth = 1, position = "identity") +
facet_wrap(~city)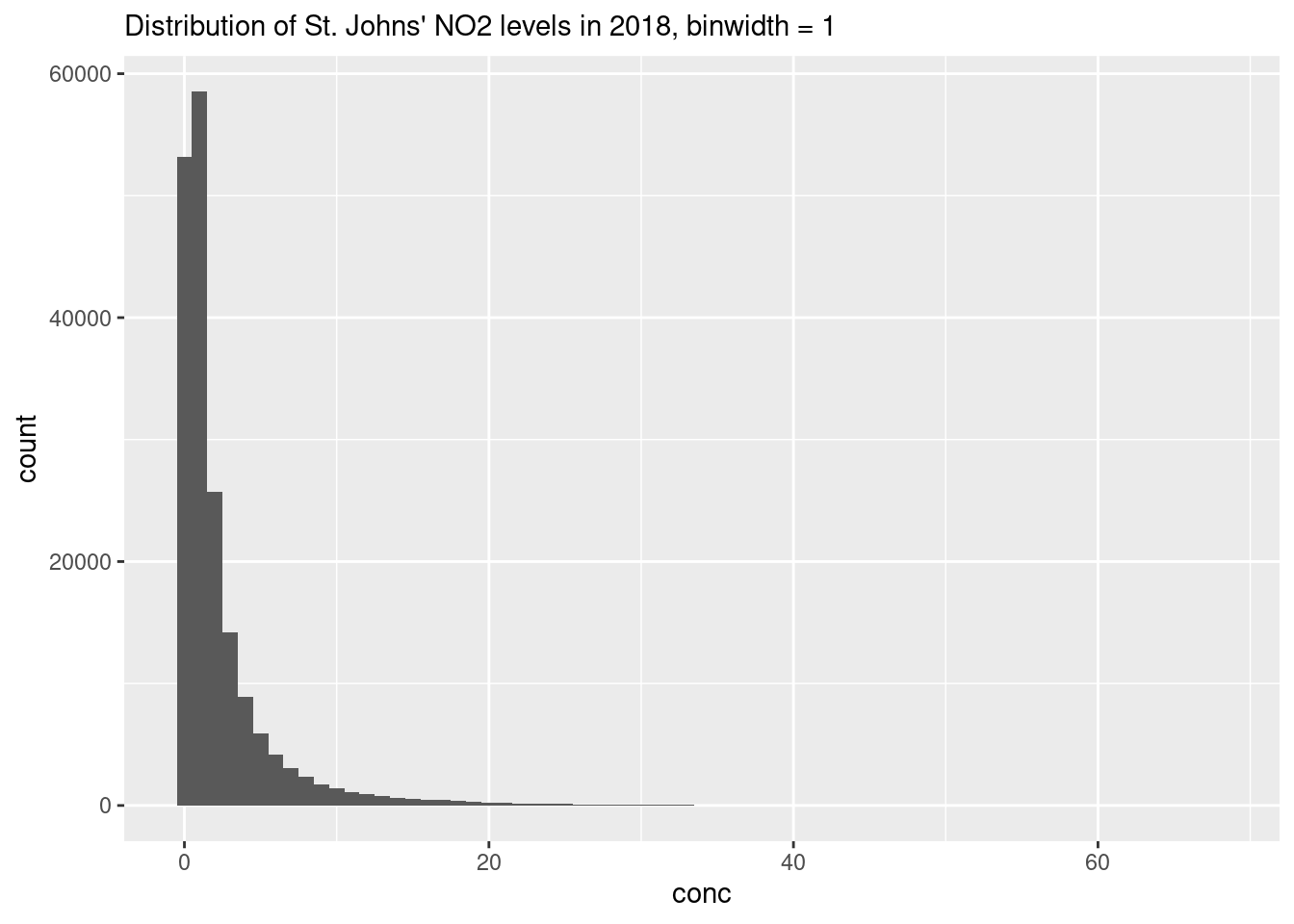
17.4 Scatter Plots
Scatter plots display values of two variables, one of which is a continuous variable. Each data point is plotted as an individual point. You’ve already learned the basics of scatter plots in Ggplot Basic Visualizations. Now, we’ll touch upon some things you can do to improve your scatter plots.
17.4.1 Marginal plots
You can easily combine a scatter plot with marginal plot. This is useful to summarize one dimension of our scatter plot. With the Toronto air quality data that we’ve already familiarized with, we might want to know the distribution of concentrations of the individual pollutants. Using the ggExtra package and the ggMarginal() function we can get the following:
## Rows: 507 Columns: 8
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (3): city, p, pollutant
## dbl (4): naps, latitude, longitude, concentration
## dttm (1): date.time
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.# note we're storing our plot in the variable torPlot
# and we're not plotting SO2
torPlot <- ggplot(data = filter(torontoAir, pollutant != "SO2"),
aes(x = date.time,
y = concentration,
colour = pollutant)) +
geom_point() +
theme(legend.position = "bottom")
# We're passing our torPlot to the ggMarginal Function
ggExtra::ggMarginal(torPlot, margins = "y", groupColour = TRUE, groupFill = TRUE)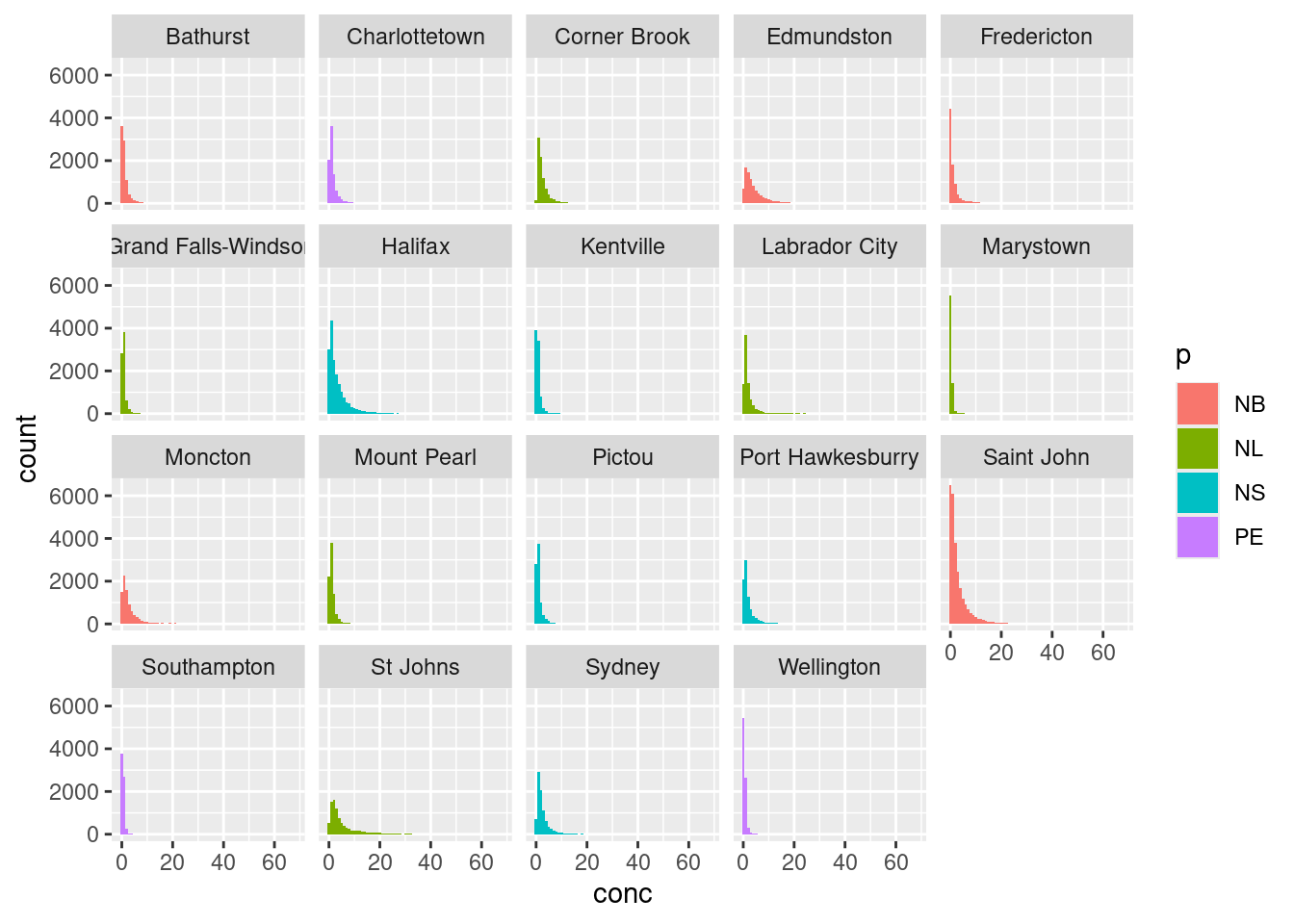
We can now see the distributions of NO2 and O3 overlaid on the vertical axis. Note that ggMarginal() only works with scatter plots.
There are plenty of other marginal options scattered about various packages. You can see many of them in action (with beautiful examples) at Tufte in R by Lukasz Piwek.
17.5 Exercise
There is a set of exercises available for this chapter!
Not sure how to access and work on the exercise Rmd files?
Refer to Running Tests for Your Exercises for step-by-step instructions on accessing the exercises and working within the UofT JupyterHub’s RStudio environment.
Alternatively, if you’d like to simply access the individual files, you can download them directly from this repository.
Always remember to save your progress regularly and consult the textbook’s guidelines for submitting your completed exercises.